Projects
What I'm working on.
One product in closed beta, a few experiments, and the system I used to teach myself how AI actually works. Built to solve real problems and to learn by doing, not a class that will be obsolete in 6 months.
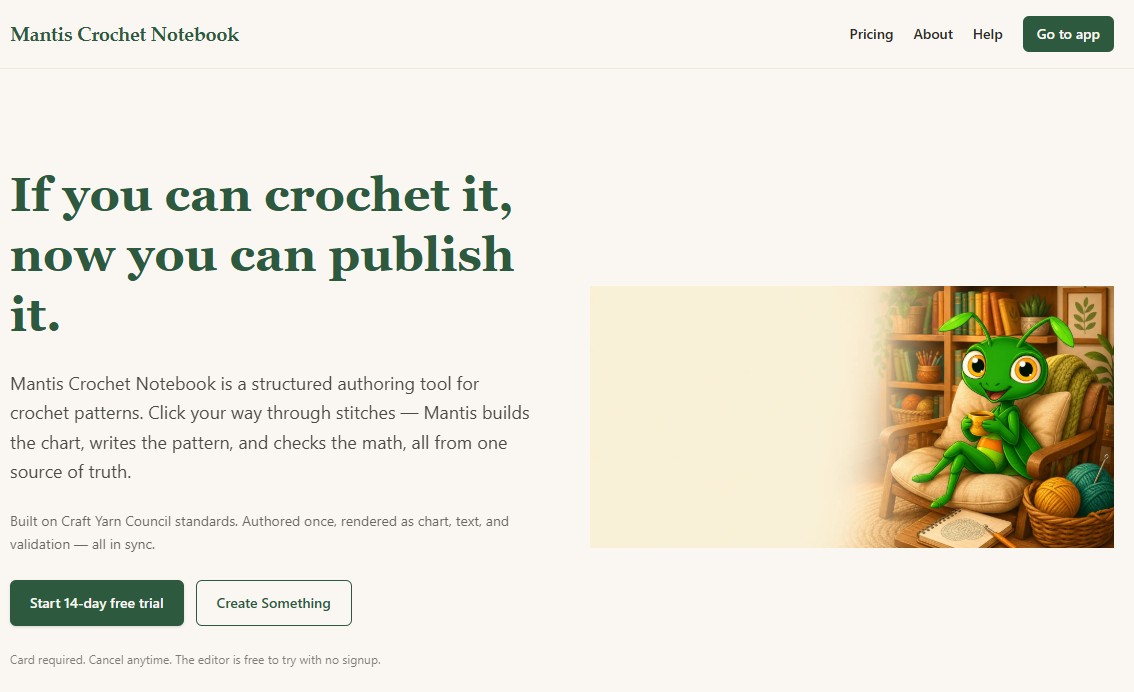
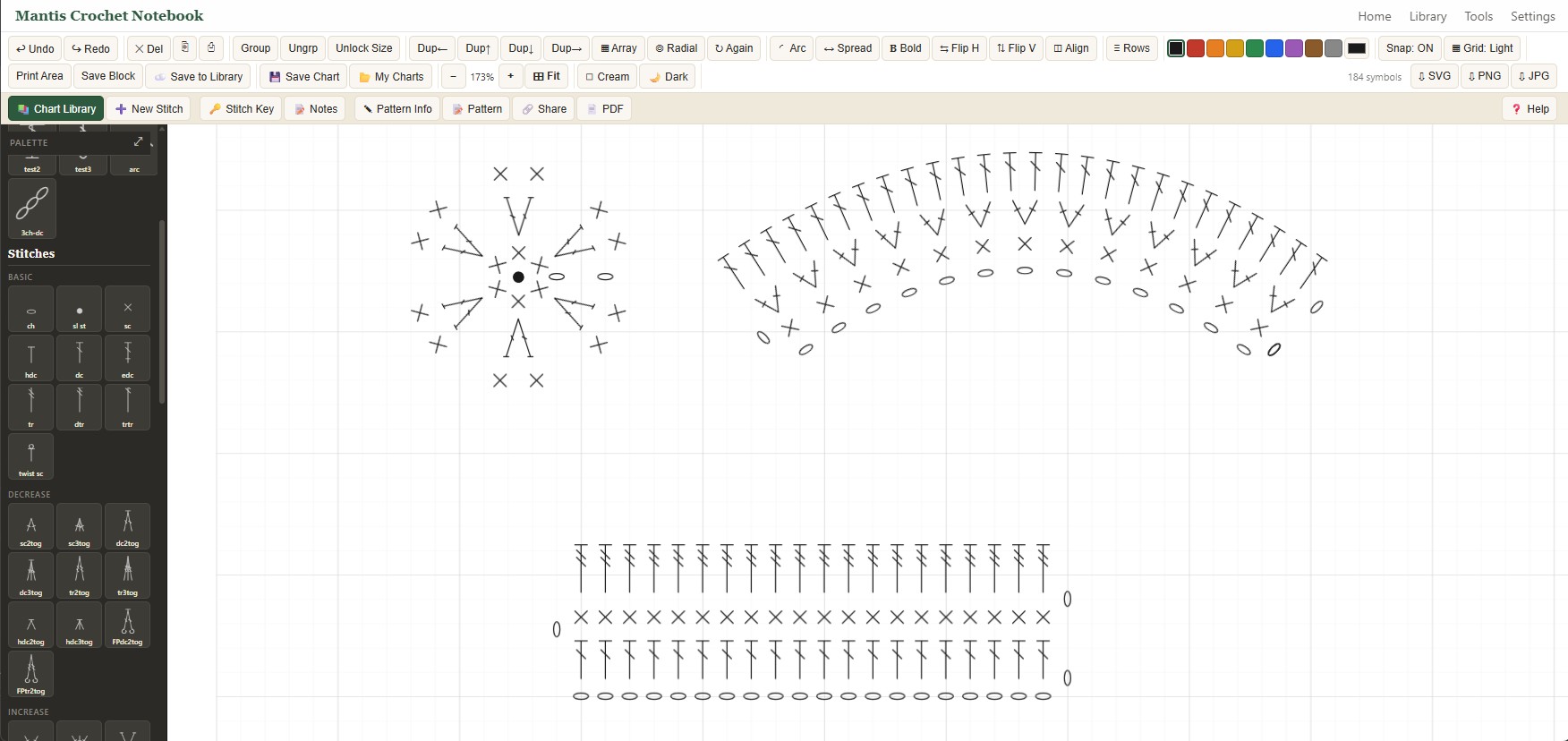
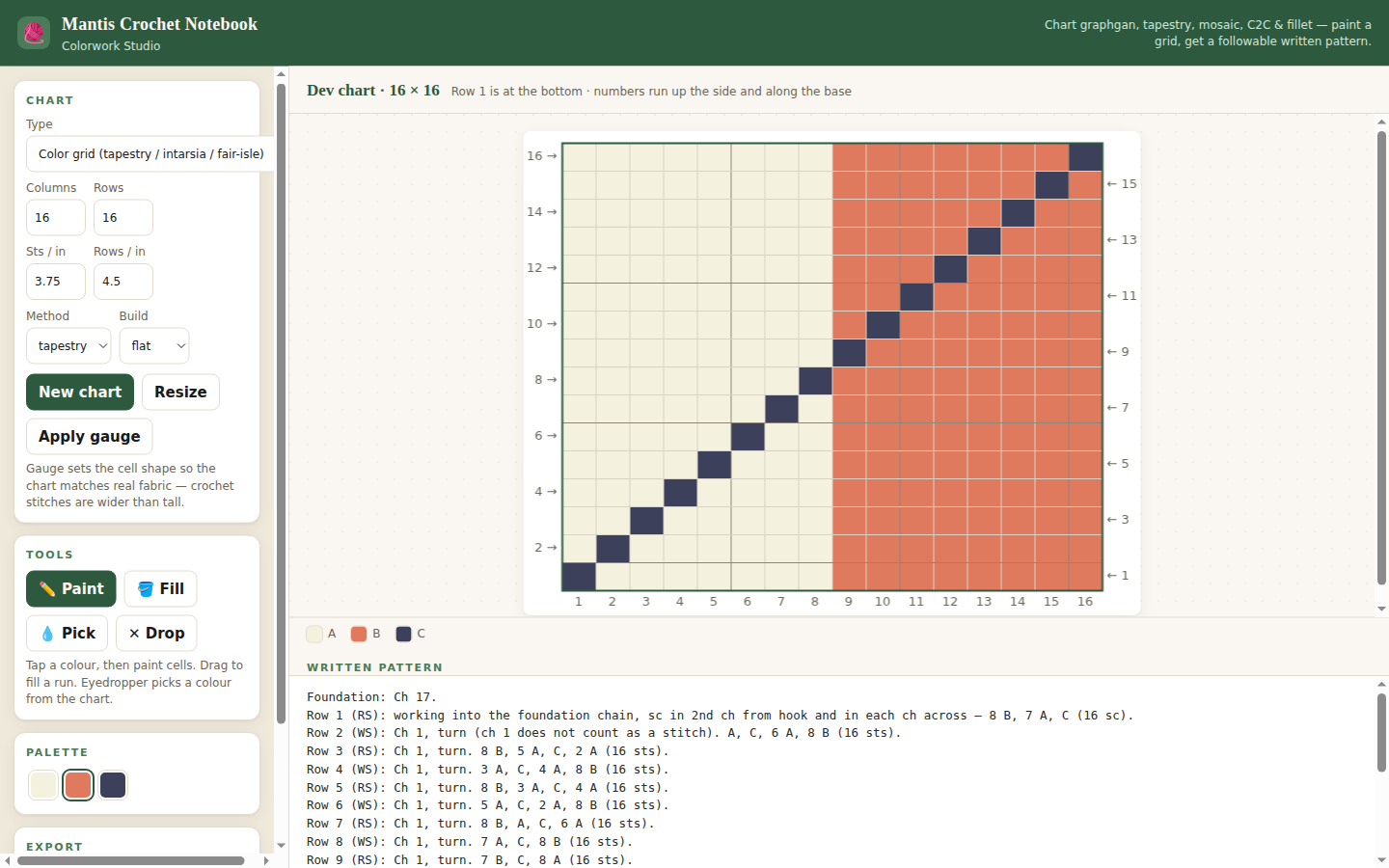
Best on desktop or iPad. Full mobile support is in progress.
The problem
Charting crochet by hand is slow, and the existing tools fight you. Most place each stitch on a rigid grid, which looks fine but breaks the actual stitch relationships, where each stitch is worked into the one below it. And a finished pattern needs a chart, written instructions, and the stitch math to all agree, which usually means building it three times.
The build
A single structured pattern model is the source of truth. The chart, the written text in standard notation, and the cooking-mode walkthrough are all views of it, so they can't disagree. The layout engine places each stitch against its previous-row anchor, not a fixed grid, so the relationships stay semantically valid. A freeform PDF studio lays out the finished pattern for publishing.
What it proves
A full crochet symbol palette mapped to composable geometric primitives, plus the discipline to recognize a hard layout problem and build a real constraint solver instead of faking it with an approximation. Pattern scaling, garment schematics, and a publish-quality PDF studio sit on top of the same model.
Where it's going
It's entering beta now, invite-only and free, with no AI in the tool itself. Sibling knit and colorwork studios are in alpha, each with its own working editor, expanding the family beyond crochet.
Notable decisions
Stitch ontology as single source of truth
All stitch geometry is defined in fractions of a slot unit S, no magic numbers anywhere in the codebase. Every renderer, whether browser-side or server-side batch generation, imports the same ontology. Constraints are named objects with CYC standard references. The alternative was hardcoded geometry per renderer, which drifted the moment two renderers disagreed.
One pattern model, many views
The chart, the written instructions, and the cooking-mode walkthrough are all rendered from one structured pattern model, not maintained separately. Change the model and every view updates together. The alternative, letting the chart and the text drift apart, is exactly the bug that makes most pattern tools untrustworthy. It also keeps the door open: the same model feeds pattern scaling, garment schematics, and the PDF studio without re-deriving anything.
Stateless renderer driven by canonical schema
The SVG renderer decides nothing. A canonical row plan, a typed JSON schema specifying every stitch, column position, row direction, and turning chain status, is fully resolved before the first line is drawn. Same input always produces the same output. This enables batch quality testing across patterns and makes rendering bugs trivially reproducible. The alternative was resolving geometry at draw time, where debugging was guesswork.
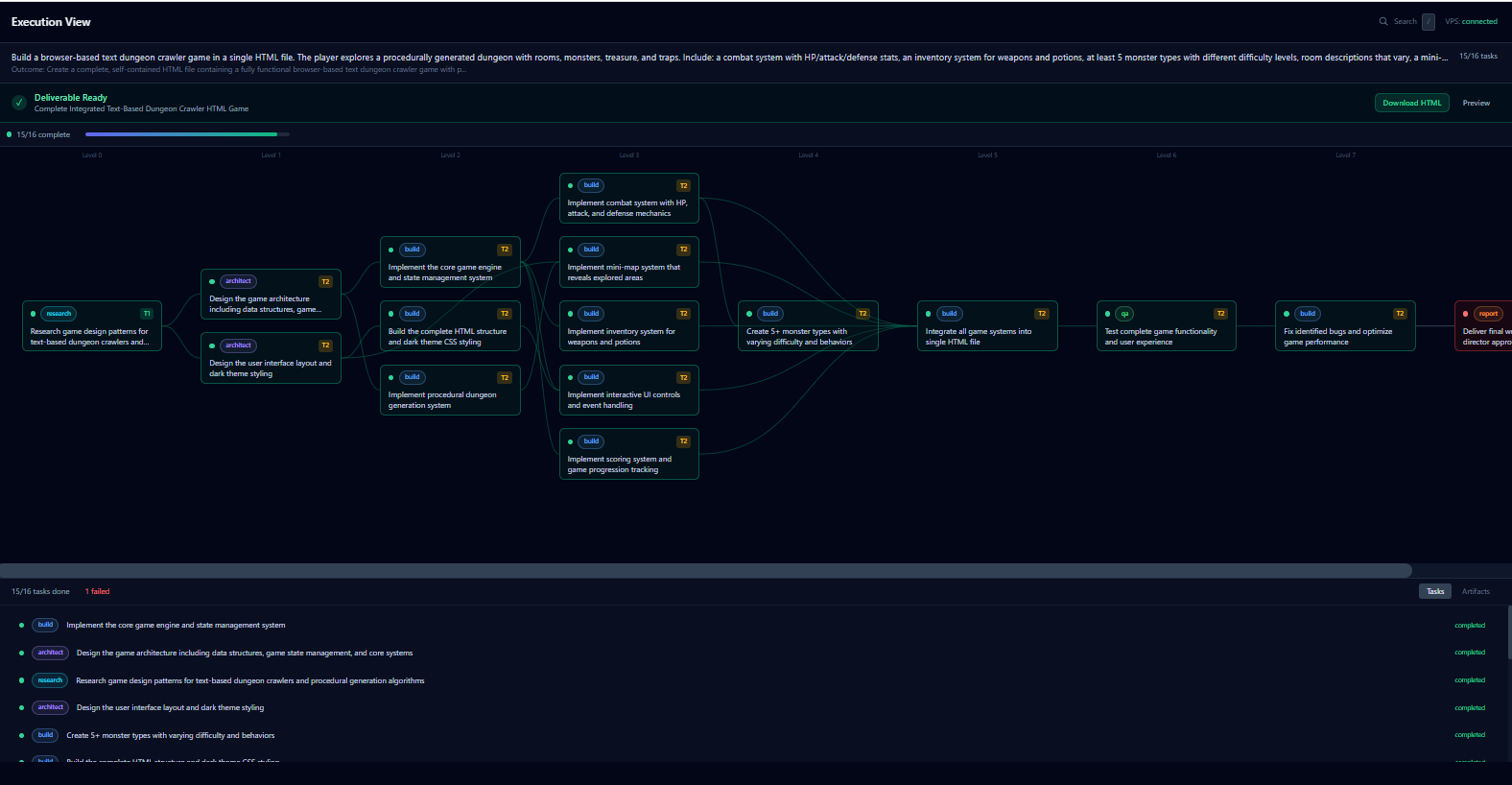
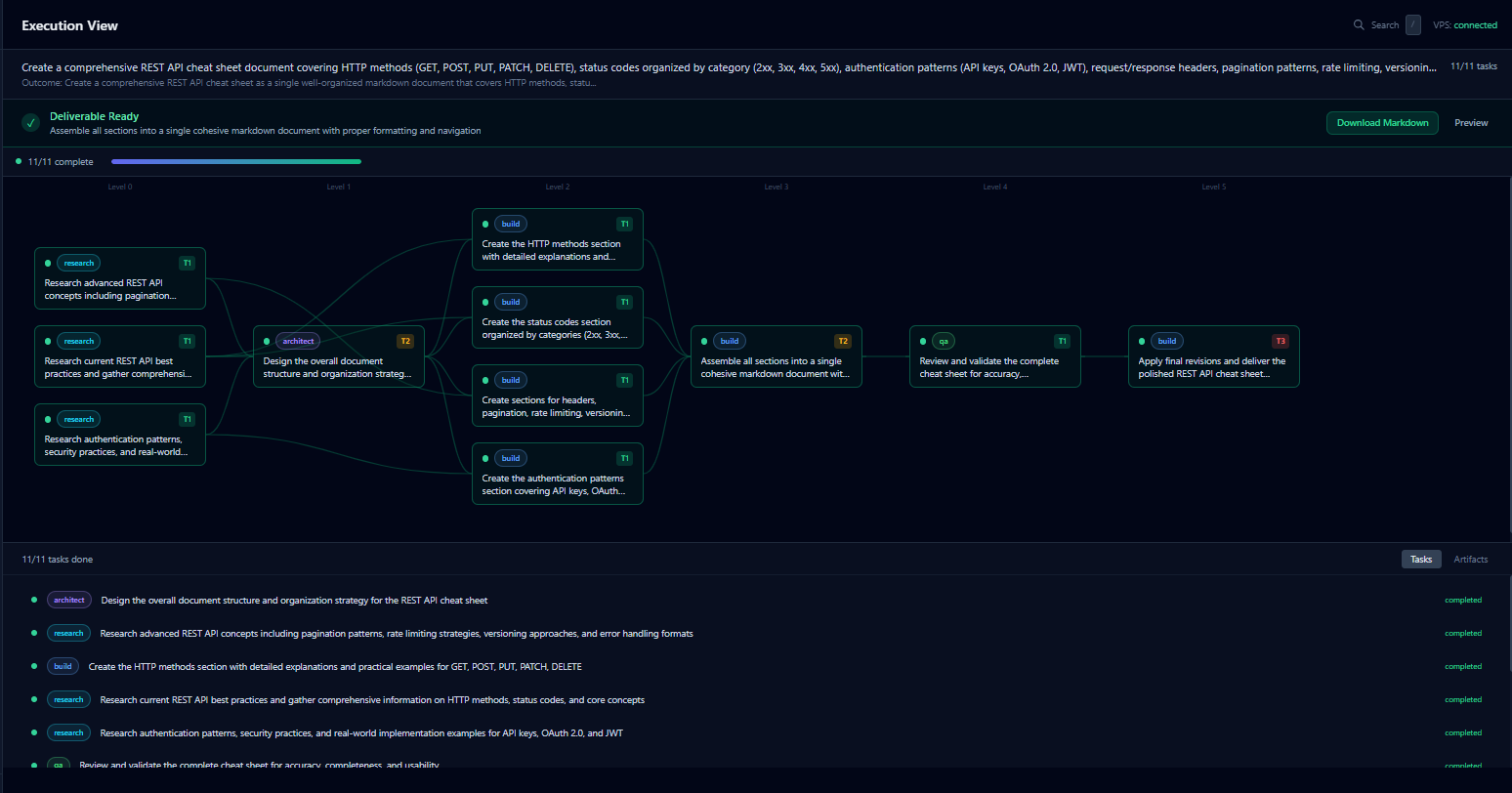
Execution views
System views
The problem
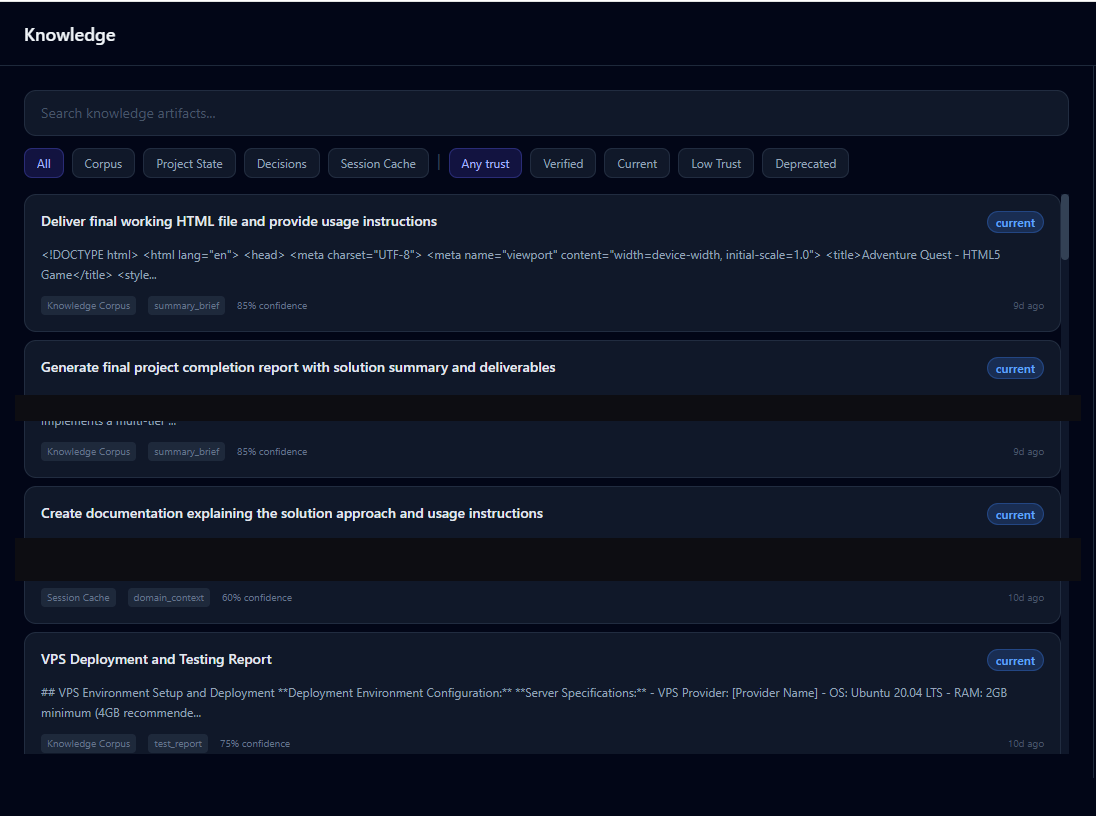
When I started this learning adventure, most AI tools required constant direction, prompt, review, redirect, repeat. The ceiling on what one person could accomplish stayed somewhat low. The goal here was different: submit intent once, and the system executes to completion, only surfacing decisions that genuinely required human judgment.
The build
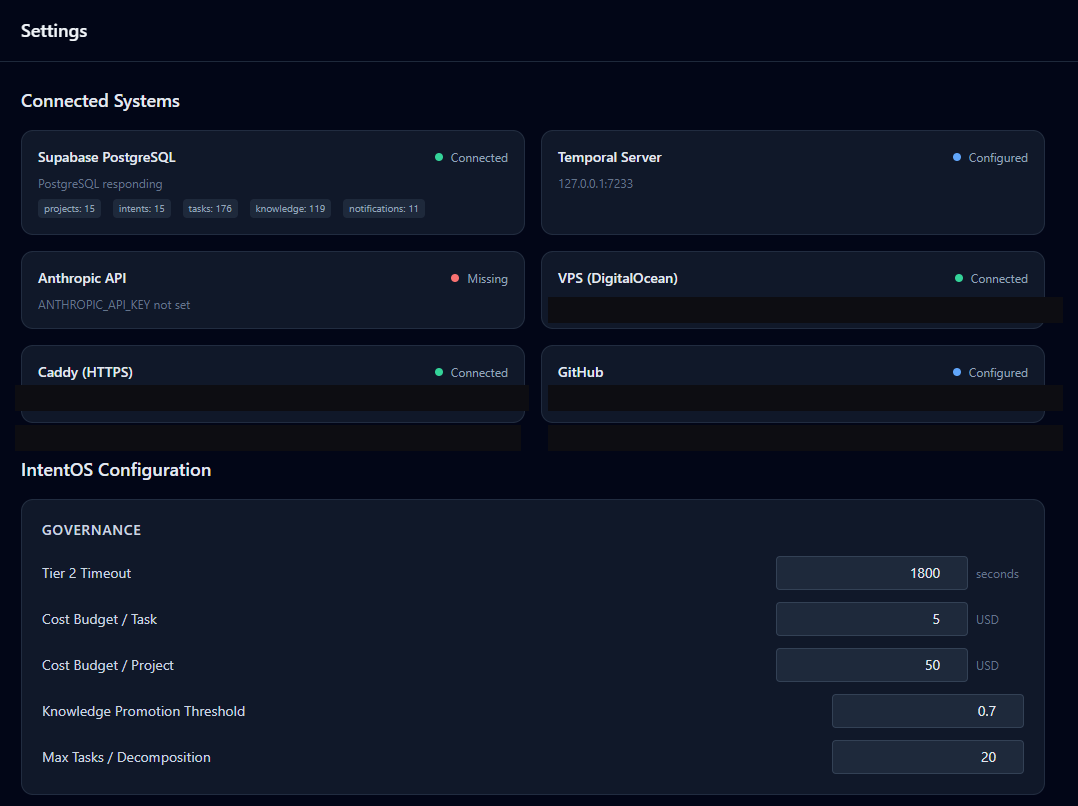
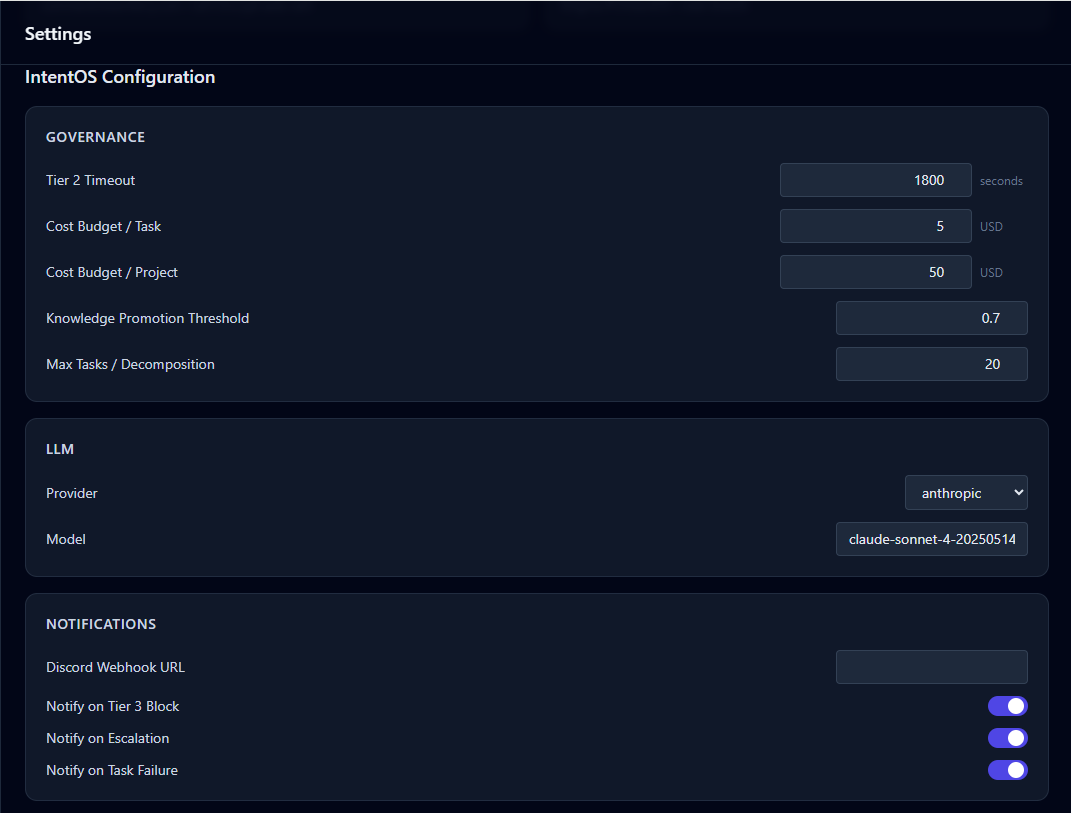
TypeScript, Node.js, Temporal durable workflows for orchestration, PostgreSQL with pgvector for a self-compounding knowledge layer, Next.js 15 command center with DAG visualization. Three-tier governance: autonomous execution, flagged review, and blocking approval, director involvement only at genuinely consequential moments.
What it taught me
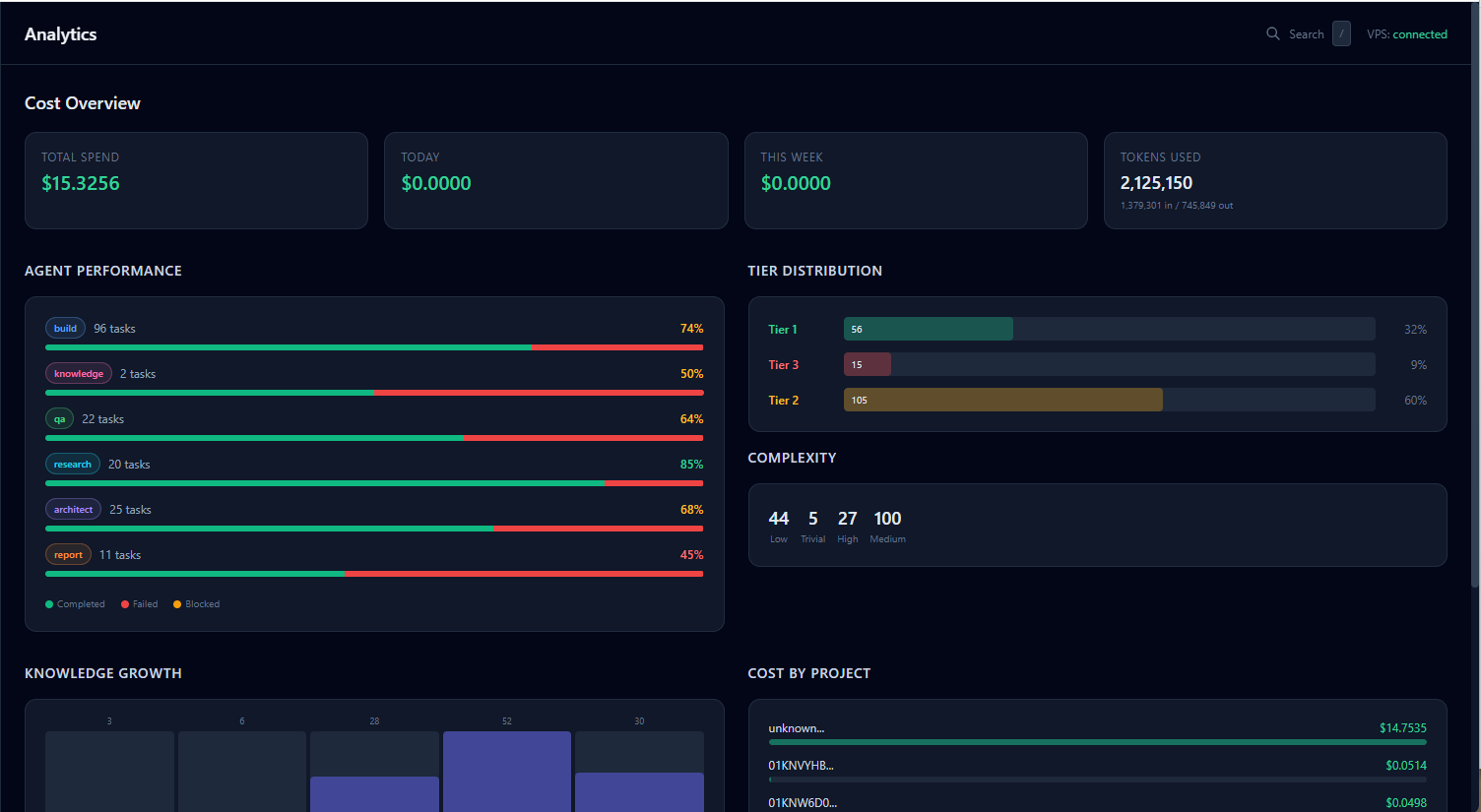
107 passing tests, running on a hardened DigitalOcean VPS, several real projects executed end-to-end. I started with no software background and used it to learn orchestration, durable workflows, agent design, and a self-compounding knowledge layer from the ground up.
The design philosophy
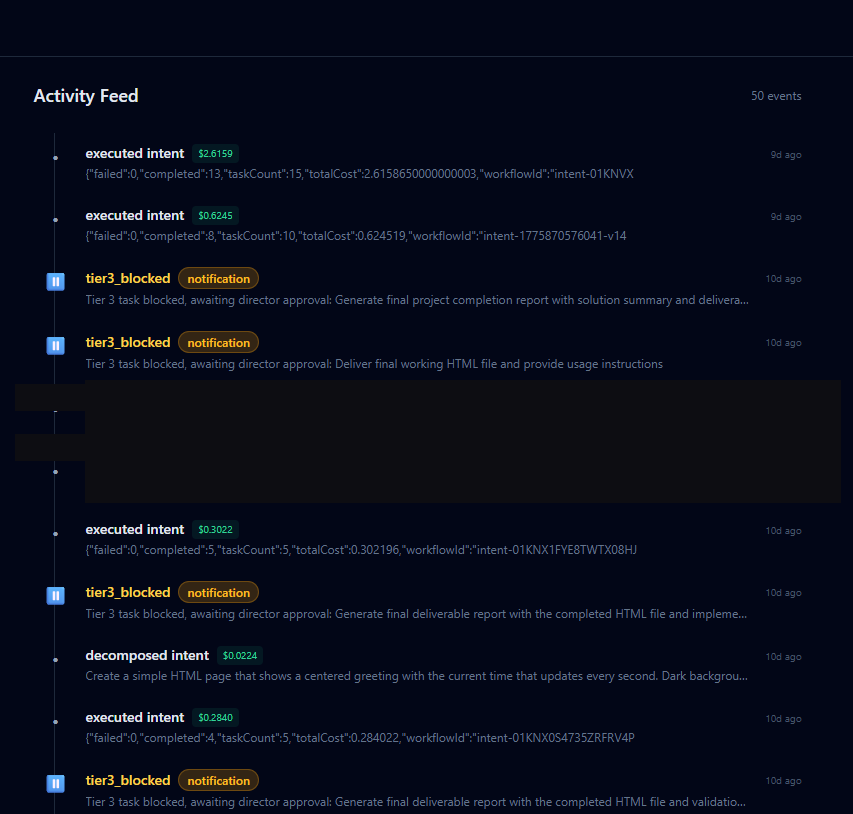
The part I'm proudest of here is the governance model. Three tiers: let it run on its own, flag a decision for review, or stop and wait for a human. Autonomous is fine until it isn't, and the system has to know the difference. That's the operations instinct, and it's the piece that still feels genuinely mine. I built the layer that decides when the system is allowed to act on its own and when it has to stop and ask, graded by how consequential the action is.
Notable decisions
Three-tier Temporal signal architecture
Tier 1 executes autonomously. Tier 2 completes and queues for async director review, so the graph keeps moving. Tier 3 sends a Temporal signal and genuinely pauses execution until the director responds. Not a flag, not a poll, but a durable workflow wait state. The alternative was all-or-nothing blocking, which would stall the entire graph on every consequential step.
Priority-respecting topological sort
Standard Kahn's algorithm picks arbitrary ready nodes. This implementation re-sorts the queue by task priority after every dequeue, not just at the roots, so high-priority research tasks always run before low-priority scaffolding, even when the graph says both are available. The re-sort on every iteration is the detail most implementations skip.
Lazy pgvector with deterministic classification
Knowledge artifacts are classified by agent role via a static lookup table, zero LLM cost, zero latency. Vector embeddings are generated lazily on first semantic query, not on insert. The result: a self-compounding knowledge layer that doesn't add overhead to every task execution, only to the retrievals that actually need it.
Canon-Lock Generation Pipeline
Critic failures and human rejections loop back to Reviser, output doesn't advance until both gates pass
The problem
High-volume AI content generation drifts. Without strict constraints, every character sounds like the same encyclopedia entry. The project required distinct tonal registers per character type, some guarded and reptilian, some matter-of-fact, some archaic and measured, enforced consistently across hundreds of documents.
The build
An extensive canonical voice guide is read by every generation task before producing output. 17 custom Python tools manage content cataloging, consistency checking, gap analysis, and stub filling. An Astro-based documentation site surfaces the world bible. Underneath it sit four constructed languages, each with three historical eras (modern, middle, ancient) generated by a deterministic rule engine. Learn a language's sound laws and you can read its older texts, with the same input always producing the same output.
What it proves
270 world-bible entries, 17 custom tools, 15 game design documents. The discipline to define the problem before generating content, build tools instead of copy-pasting prompts, and enforce quality gates before anything is marked canon.
The design philosophy
AI without governance produces noise. The canon-lock workflow, brief, voice check, AI draft, human review, canon, ensures every output earns its place. The same pattern applies anywhere high-volume AI content needs to stay on-voice at scale.
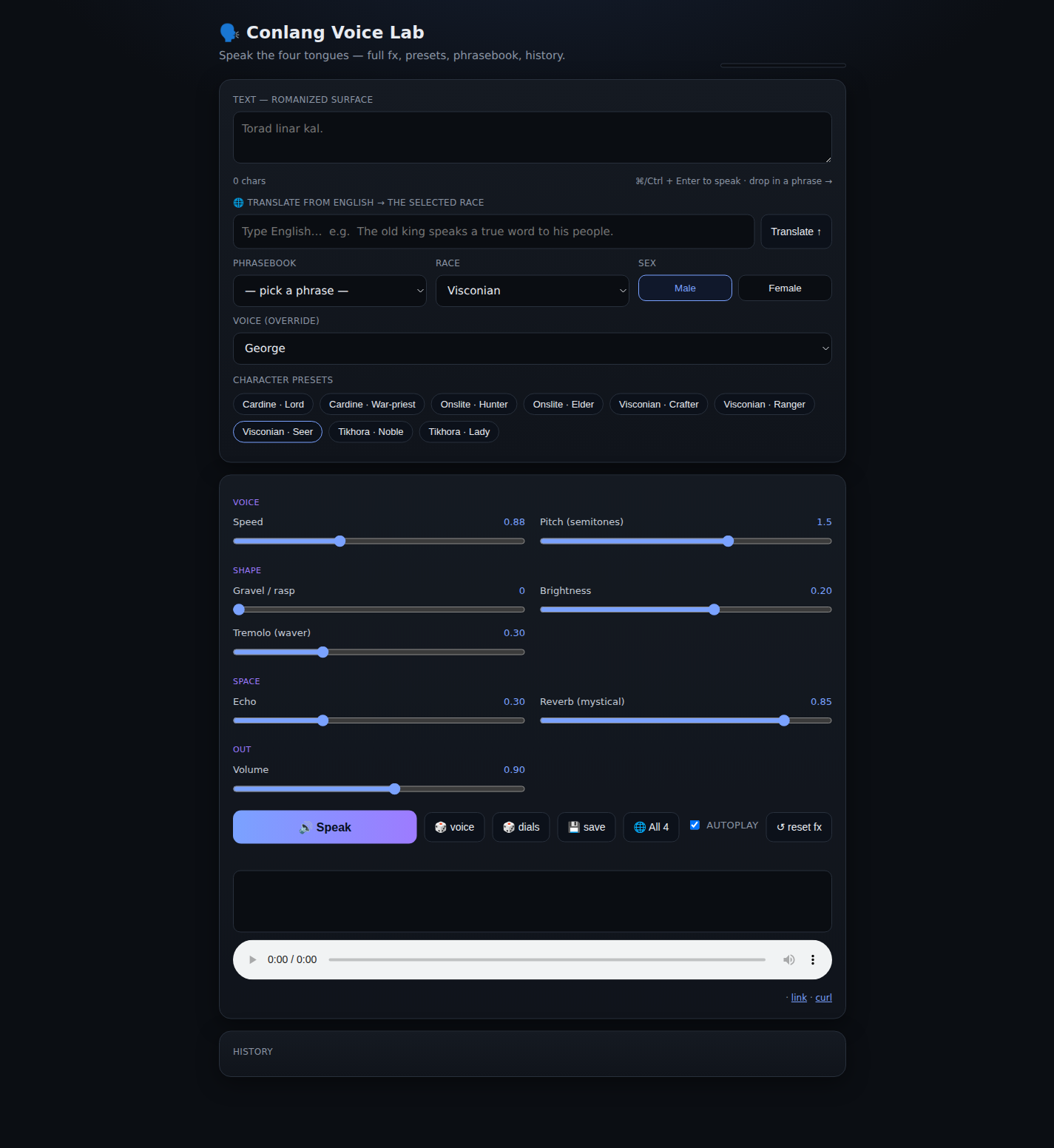
Four constructed languages
Underneath the world sit four full constructed languages: Cardine, Tikhora, Onslite, and Visconian. Each exists in three historical eras, modern, middle, and ancient, and they aren't set dressing. A deterministic rule engine, not an AI, derives every word. The ancient form is the source of truth, and a set of sound laws erodes it forward into the modern tongue, the same way real languages drift over centuries. Learn a language's sound laws and you can read its older texts, and the same input always produces the same word, so a line written in one of them has exactly one correct reading.
Notable decisions
Extensive canonical guide as injected system context
Every generation task (NPC entries, location descriptions, in-world documents) receives the full voice guide before producing a word. Not a summary, not a reminder: the full specification. A session that never saw prior output still produces content indistinguishable in tone from work written months earlier. The guide is the consistency; everything else is execution.
Canon-lock: AI critique before human review
Brief → AI write → AI critique → AI revise → human review → canon commit. The critic catches voice drift and generic phrasing before the human sees anything. Human judgment is reserved for canon decisions, not proofreading. The result: consistent output at high volume without constant intervention. Nothing enters the world bible without passing both gates.
17 purpose-built tools instead of managed prompts
Gap analysis, stub filling, consistency checking, content cataloging. Each is a Python tool, not a prompt to copy-paste. The tools query existing canon, identify what's missing, and generate targeted briefs. This is the difference between a scalable pipeline and a good prompt library. 270+ entries produced; the tooling is why it's consistent at that volume.
Sample Output
Two samples from the world bible, in-world accounts written entirely through the canon-lock loop, each held to a single character's voice. These two stood on opposite sides of the same vote:
Pages from the Watching-Book of Tarrin Burrow-Born
I voted against the action and I will perform my role within the action. This is what an oath is for, and I would not be a man worth keeping the oath if I did not also keep the part of it I had argued against.
I have not cried since the vote was called and I do not intend to. There is work in front of me.
Read the full account →What I Saw at the River Bend
They came at the hour when the light has left the sky but the water still holds it. The first one I saw was not the eldest. The first one I saw was a young Onslite, perhaps half my age, half-crouched at the tree line with his weight forward and his head tilted to listen. He had been there for some span of seconds before I noticed him, which I have thought about often since. He chose to be unseen.
He saw me see him. The look went on long enough that I understood he was deciding whether to bring the rest forward, and that my next motion would settle it. I sat down on the moss. I did not stand. I did not draw. I sat down on the wet moss with my hands open on my knees, and I waited.
Read the full account →Single Voice → Multiple Characters
What it does
Takes raw recorded audio, segments by speaker and character, and applies AI-powered voice transformation to each segment using the ElevenLabs API. The two-character pipeline handles segmentation, voice assignment, and output assembly end-to-end.
What it proves
Multi-step AI API integration doesn't require a team or a sprint. The pipeline demonstrates what moves fast when the problem is clearly defined and the tools are well-chosen. The same orchestration pattern (ingest, transform, route, assemble) scales to significantly larger multimedia applications.
Before & After
One recording session. One voice. Two distinct characters.
Audio samples coming soon, recordings in progress
Notable decisions
Cue-based character detection at record time
Routing decisions are embedded in the recording itself. "Nova says:" is a directive, not metadata added later. This eliminates a post-processing classification step entirely. The speaker sets routing intent at the moment of recording; the pipeline just executes it. One session, one voice, complete routing information embedded throughout.
One recording session yields multiple distinct voices
Traditional multi-character audio requires separate recording sessions per voice actor. This pipeline collapses that to a single take: record all dialogue in sequence, cue characters by name, let the pipeline handle the rest. Re-recording a single line means re-recording one segment, not a session per character. Fast iteration at every step.
Independent voice profiles per character
Each character maps to an independent ElevenLabs voice profile. Adding a new character requires a new profile and a new cue prefix, no changes to the segmentation or assembly logic. The same pipeline that handles two characters handles ten. The orchestration pattern scales horizontally; the processing code doesn't change.